AI Agent Observability: Why You Can't Debug What You Can't See
Your AI agent didn't crash. It returned a clean, confident answer — and it was completely wrong. No error in your logs, no alert in your dashboard, no stack trace to follow. The failure happened three steps earlier, when the agent called the wrong tool, got bad data, and carried that bad data into every decision after it. By the time the wrong answer reached your user, your monitoring had already moved on.
Traditional dashboards don't see this. AI agent observability does.
It reconstructs every step your agent took — every tool call, every decision, every piece of context it carried forward — so the next time your agent goes wrong, you find out before your user does.
That gap is why observability has become its own discipline rather than an after thought bolted onto regular application monitoring. I've written in this series about loop engineering, the practice of designing loops that run agents on a schedule, and about context engineering, the discipline of managing what an agent actually sees. I've also covered multi-agent orchestration, where several agents divide a task between them. Observability is the layer that makes all three of those actually debuggable in production. Without it, you're shipping agentic systems you can watch work but can't explain when they don't.
This guide covers what AI agent observability actually means, the specific ways agents fail that traditional monitoring misses entirely, what to trace at each step of an agent's execution, and how to think about picking a stack instead of just a vendor.
What Is AI Agent Observability?
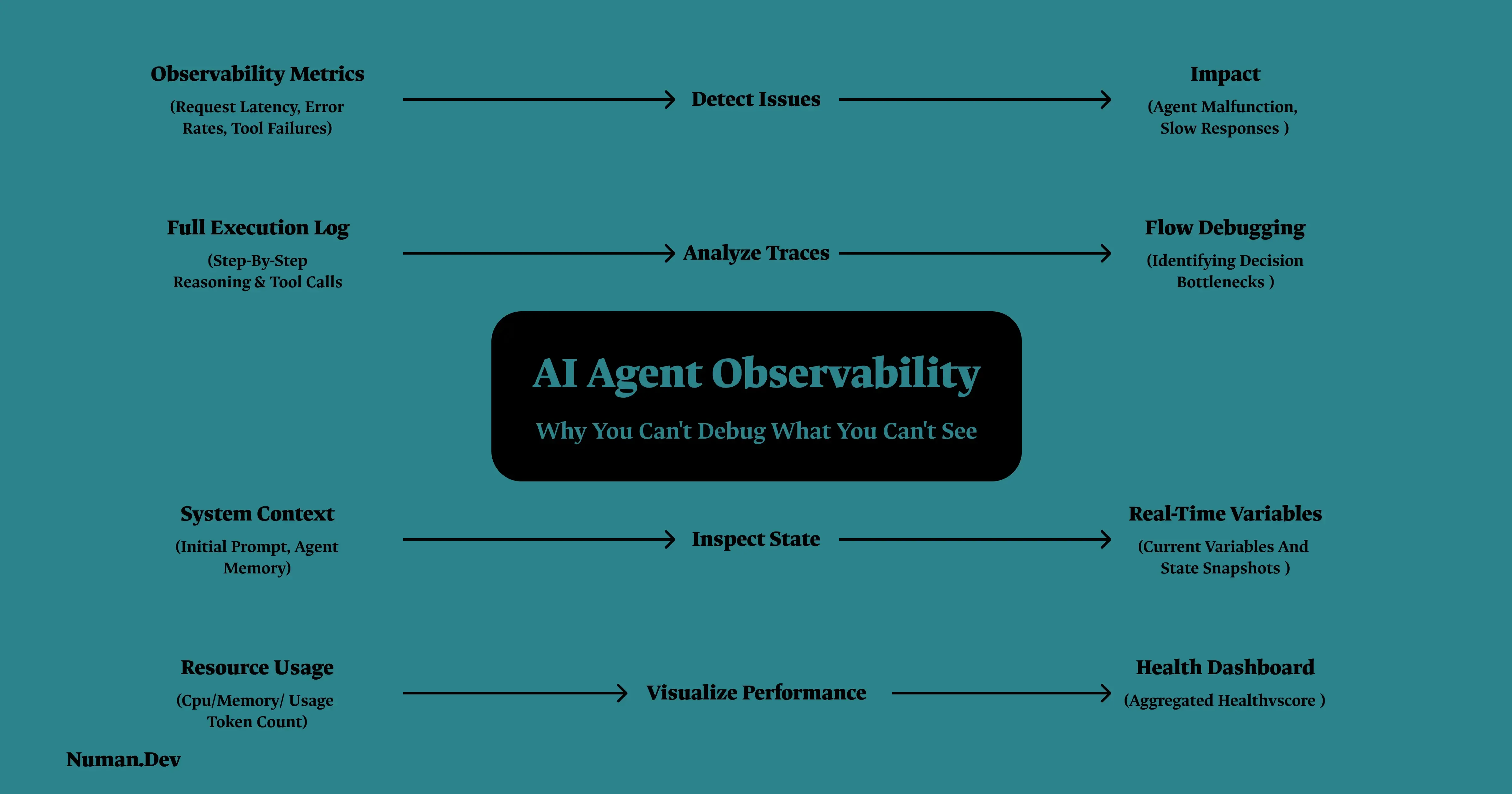
AI agent observability is the practice of instrumenting and monitoring AI systems in production to gain visibility into their inputs, outputs, execution traces, retrieval steps, tool calls, latency, cost, and behavioral anomalies over time. It means capturing every model call and reasoning step as a structured span, so that when something goes wrong, you can actually answer why.
The distinction from traditional infrastructure monitoring matters. Uptime, latency, and error rate monitoring tell you a service is responding. They tell you nothing about whether what it returned was correct, or whether the reasoning that produced it made sense. AI observability platforms add a layer underneath that: visibility into model behavior and semantic correctness, not just whether a request completed.
Why Agents Fail in Ways Regular Monitoring Can't Catch
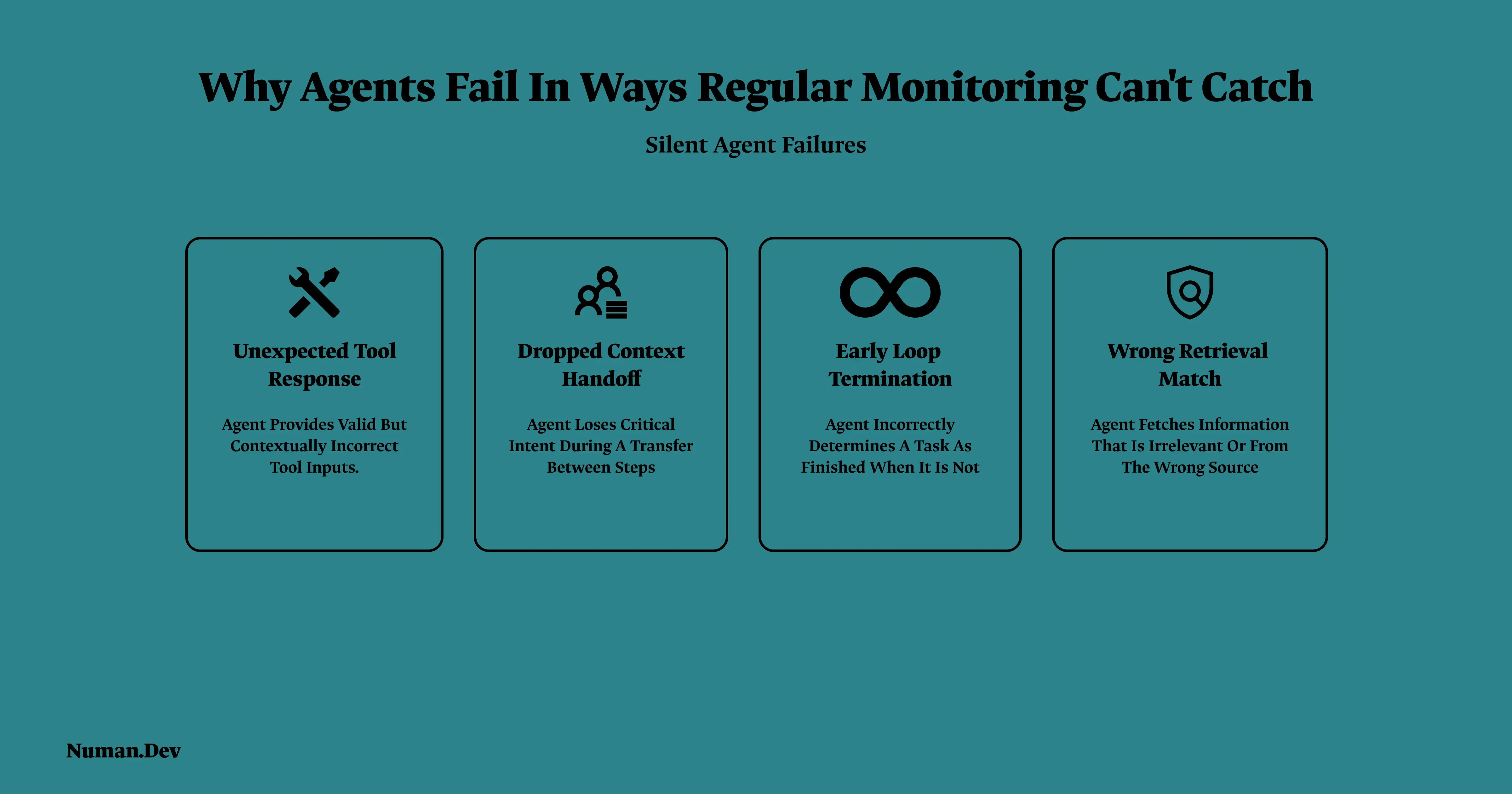
A single call LLM request fails in mostly visible ways: bad output, an obvious error, a timeout. Agents fail differently, because they fail across steps rather than in one shot, and each of those step level failures can look completely fine in isolation.
A tool call returns a response in an unexpected structure, and the agent works around it instead of erroring out, silently producing a worse answer rather than failing visibly. A context handoff between agents or sessions drops a piece of state nobody notices is missing until three steps later. A loop terminates early because its completion signal fired on a half finished task. A retrieval step pulls a document that's semantically close to the query but factually wrong, and the agent reasons confidently from incorrect material. None of these trip a traditional error handler. All of them degrade output quality, and without step level visibility into the agent's actual decisions, simple request logs won't surface any of it.
This is also why the volume of context an agent has access to isn't the bottleneck most teams assume it is. Recent analysis of production agent traces found that context quality, not volume, is the real limiting factor. Most teams don't come close to using the full context window available to them, which shifts the real engineering problem from managing the token count to understanding which information is actually driving the model's decisions. Observability is what lets you see that distinction instead of guessing at it.
What to Actually Trace
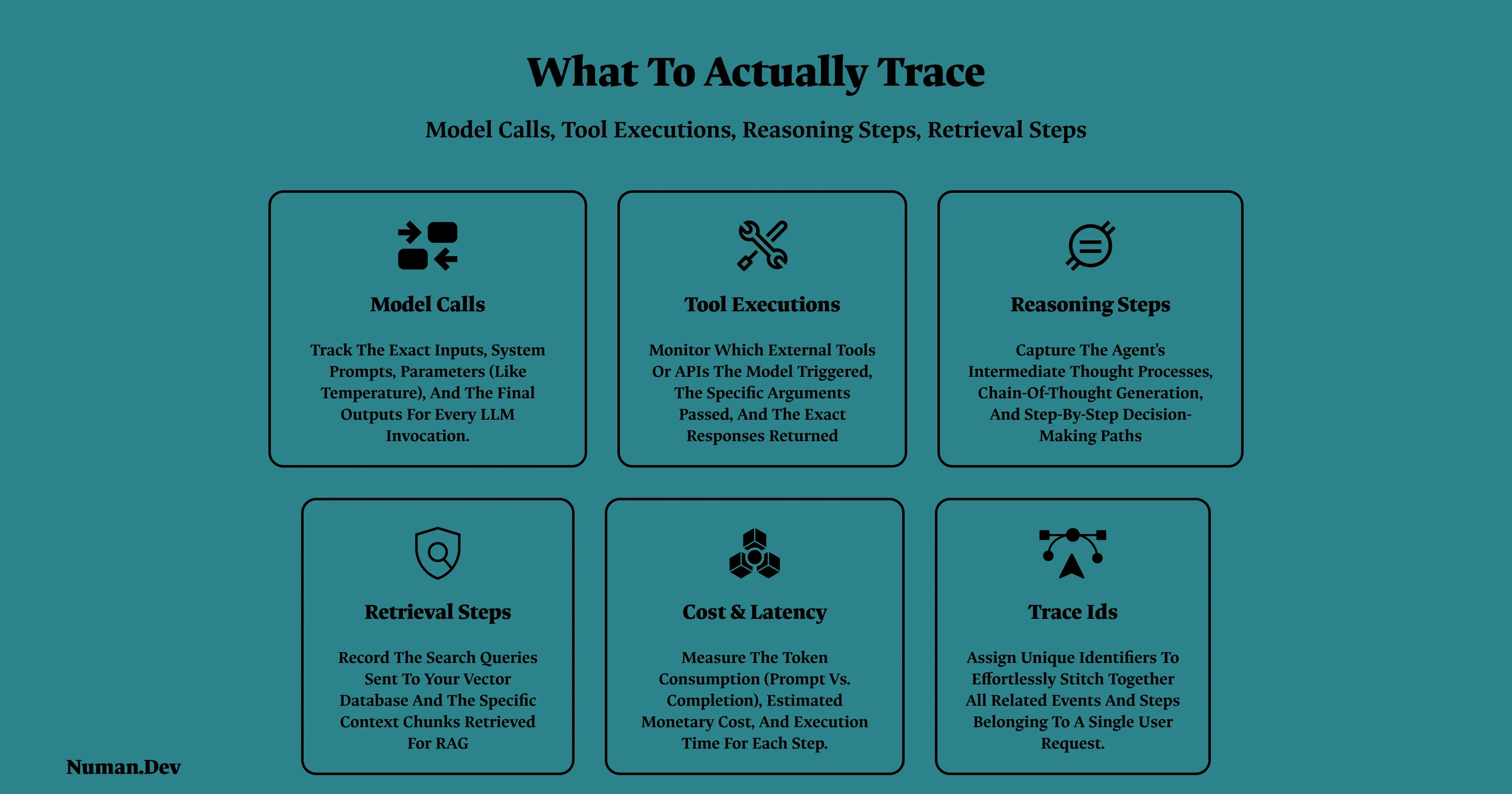
Effective agent observability captures a specific set of signals at each step, not just the final input and output.
Model calls: Every prompt sent and response received, including the system prompt and any context injected at that step, not just the user facing exchange.
Tool executions: What tool was called, what arguments were passed, what came back, and how long it took. This is where the unexpected structure failure mode above gets caught, if you're actually looking at it.
Reasoning steps: For agents that expose intermediate reasoning, capturing it as its own structured span rather than burying it inside a single opaque log line is what makes a later "why did it do that" question answerable.
Retrieval steps: What was retrieved, from where, and how relevant it actually was to the query. Not just whether retrieval succeeded, but whether it retrieved the right thing.
Cost and latency per step, not just per request: A single slow or expensive tool call inside an otherwise fast agent run is invisible if you're only measuring total request time.
Trace IDs that connect every span in a single agent run end to end: so a failure three steps into a task can be traced back to the model call or context state that caused it, instead of starting the investigation from scratch.
Multi-Agent Systems Need This More, Not Less
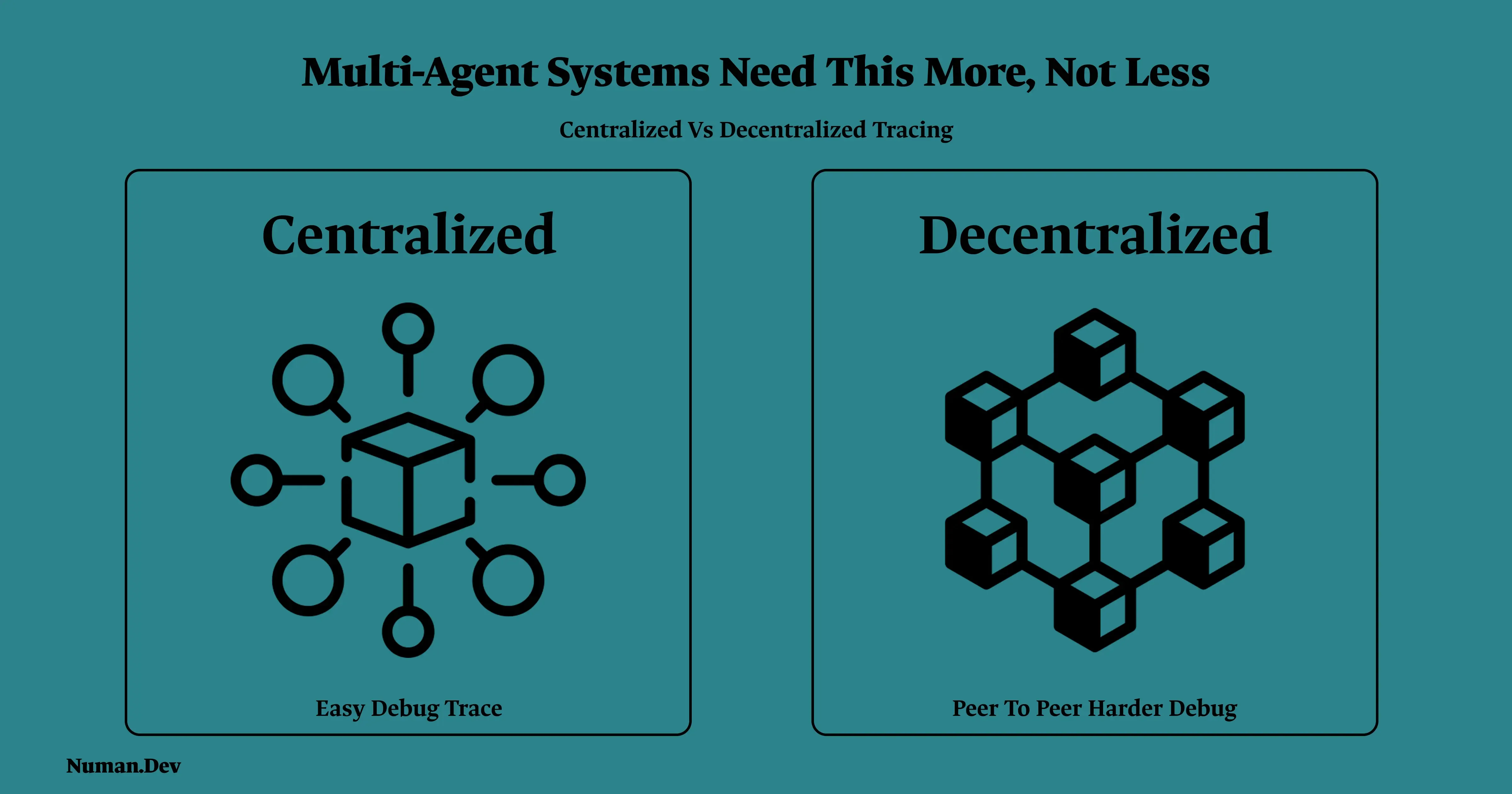
Everything above applies to a single agent. Multi-agent systems need observability more urgently, because there are more seams where things can desynchronize, and the failures specific to multi-agent orchestration are harder to catch without it.
A handoff between agents can drop context that the receiving agent then has to work without, silently. A hallucinated output from one agent can get passed downstream and treated as verified fact by the next, with the error compounding rather than staying contained. In decentralized coordination patterns specifically, where agents communicate more directly with each other instead of through a single hub, reconstructing what actually happened after a failure is significantly harder than in a centralized setup, since there's no single place all the interactions were logged. If you're running a multi-agent system without tracing that captures every agent to agent interaction, you're not really running an observable system. You're running one you can watch succeed and only guess at when it doesn't.
Building an Observability Stack: What Actually Matters

When evaluating a stack rather than guessing, a few criteria separate the tools that hold up in production from the ones that look good in a demo.
Trace depth: Does it capture prompts, model outputs, retrieval steps, and tool calls, or just the final input and output? Surface-level logging answers none of the actual debugging questions.
Evaluation workflows: Hallucination detection, automated scoring, and human feedback loops that let you compare model or prompt versions against each other, not just watch one version in isolation.
Standardization: The Open Telemetry GenAI conventions are emerging as the vendor neutral standard for this kind of tracing, which matters if you don't want your observability data locked into one vendor's proprietary format.
MCP specific tracing: if your agents use the Model Context Protocol to reach tools and data. This is becoming a meaningful differentiator between platforms as agent tool use grows more complex.
Deployment model and data residency: especially for anything handling sensitive data. Self hosted versus cloud changes both cost and compliance posture.
The honest takeaway on tooling specifically: don't pick a platform because it has the most features. Pick one based on the depth of trace you actually need for the failure modes you're most exposed to, and confirm it covers your specific stack, whether that's multi-agent, RAG heavy, or tool call heavy, rather than assuming general LLM observability covers agent specific failure patterns automatically.
Frequently Asked Questions
What is AI agent observability?
AI agent observability is the practice of tracing and monitoring autonomous agents in production by capturing every model call, tool execution, and reasoning step as structured, connected spans. So when an agent produces a wrong or unexpected result, you can trace back through its actual decisions to find out why.
How is agent observability different from regular application monitoring?
Application monitoring tracks whether a service is up, fast, and returning successful status codes. Agent observability adds visibility into semantic correctness and reasoning, whether the output was actually right, not just whether the request technically completed. A request can succeed completely and still represent an agent failure.
Why do AI agents fail silently?
Because their failures happen at the step level rather than producing an obvious error. A tool call returning an unexpected format, a context handoff dropping state, a retrieval step pulling factually wrong but semantically similar content. Each of these can look like a normal completed step without step level tracing to catch it.
Do single-agent systems need observability, or only multi-agent ones?
Both need it, but multi-agent systems need it more urgently. They have more points where context can be dropped or an error from one agent can cascade into ones downstream, and centralized logging through a single trace becomes the only practical way to reconstruct what happened across multiple agents after a failure.
The Takeaway
The thread through this whole series has been the same one. Every layer of working with AI agents, the loop, the context, the orchestration between agents, moves the real engineering work further from typing instructions and closer to designing systems you can reason about. Observability is what makes that reasoning possible after the fact instead of just during the demo.
If you're running agents in production without step level tracing, the honest state of things is that you can watch them succeed, and you're mostly guessing when they don't. That gap closes with instrumentation, not with better prompts. Trace the model calls, the tool executions, and the handoffs, and the "why did it do that" question stops being a mystery and starts being something you can actually answer.
Written by Numan, a full-stack developer working with Agentic AI, loop engineering, context engineering, and multi-agent orchestration for production mobile and web products. Get in touch if you're building something that needs this kind of engineering.