Multi-Agent Orchestration: A Practical Guide to Coordinating AI Agents Without the Coordination Overhead
A single AI agent can answer a question, write a function, or fix a bug. The moment a task is too large for one context window, too complex for one model to track end to end, or genuinely parallel, a single agent stops being the right shape for the problem and that's where multi-agent orchestration starts.
I've spent the last two articles in this series on the layers underneath orchestration: designing loops that prompt agents on a schedule, and managing the context those agents actually see. Orchestration is the layer above both deciding how multiple agents divide work, share what they've learned, and recover when one of them gets something wrong. It's also the layer where teams most often over-build. The data backs this up directly: Princeton NLP found a single agent matched or outperformed multi-agent systems on 64% of benchmarked tasks when given the same tools and context, and close to 40% of multi-agent pilots fail within six months of reaching production.
This guide covers what multi-agent orchestration actually means, the six patterns that hold up under real production load, and just as importantly when a single well-configured agent is still the better call.
Show Image
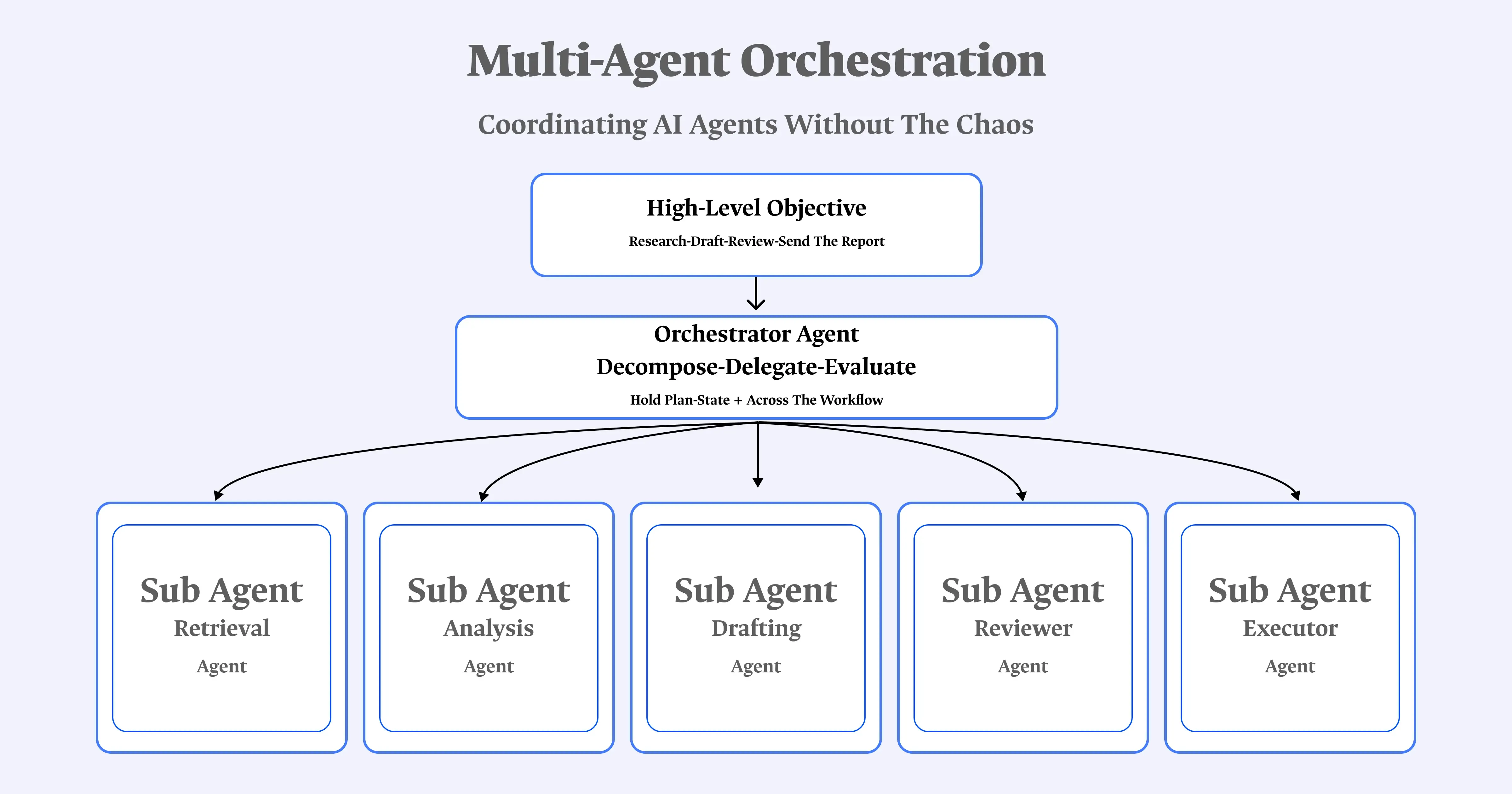
What Is Multi-Agent Orchestration?
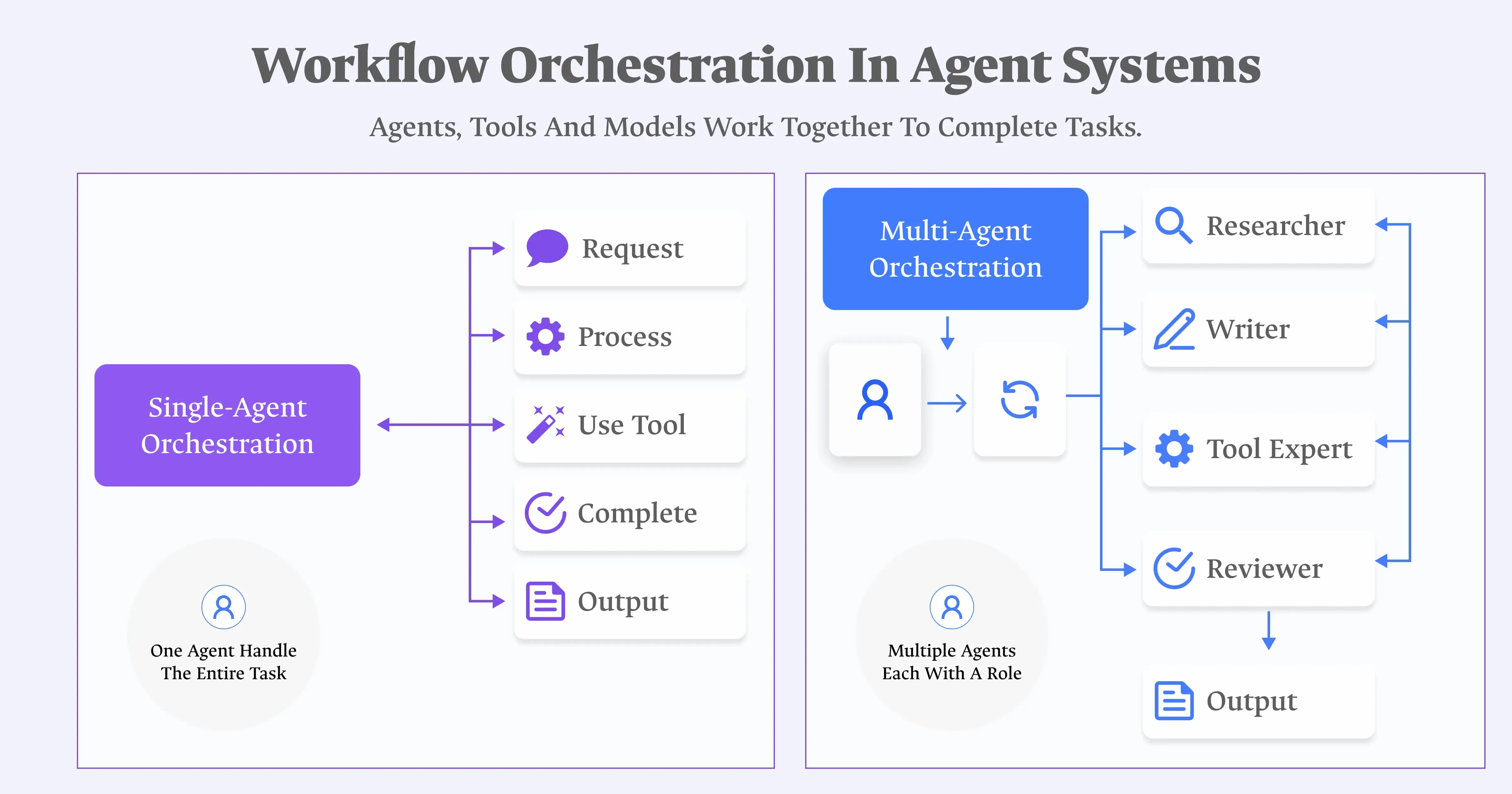
Multi-agent orchestration is the engineering discipline that coordinates multiple specialized AI agents so they divide work, share context, handle failures, and assemble a coherent result instead of one agent trying to hold an entire task in a single context window.
The single most important thing to understand before adopting it: orchestration is a coordination overhead you're choosing to take on, not a default upgrade. A single agent with the right tools and a clean context window is simpler to debug, cheaper to run, and outperforms a multi-agent setup on the majority of tasks people throw at it. Orchestration earns its complexity only when the task itself demands division of labor — not because "multi-agent" sounds more sophisticated than "single agent."
When You Actually Need Orchestration
A single agent stops being sufficient under three conditions, and it's worth checking your task against all three before reaching for an orchestration framework.
The task doesn't fit one context window
Long, multi-stage work research that spans dozens of sources, a refactor touching a large codebase — accumulates more context than one agent can hold without the early, important parts getting buried under everything that came after.
The task needs specialized expertise that doesn't compose well in one prompt
A security review and a performance review apply genuinely different judgment. Asking one agent to do both in the same pass usually produces a shallower version of each than two agents each given one job.
The task has independent, parallelizable parts
Four unrelated subtasks with no dependencies between them finish faster split across agents working concurrently than processed one after another by a single agent.
If none of these apply, the honest move is to stay with a single agent, a clean tool set, and well-managed context. Adding orchestration to a task that doesn't need it adds a coordination tax — state passing, error handling across agent boundaries, observability — without a matching gain.
The Six Orchestration Patterns That Hold Up in Production
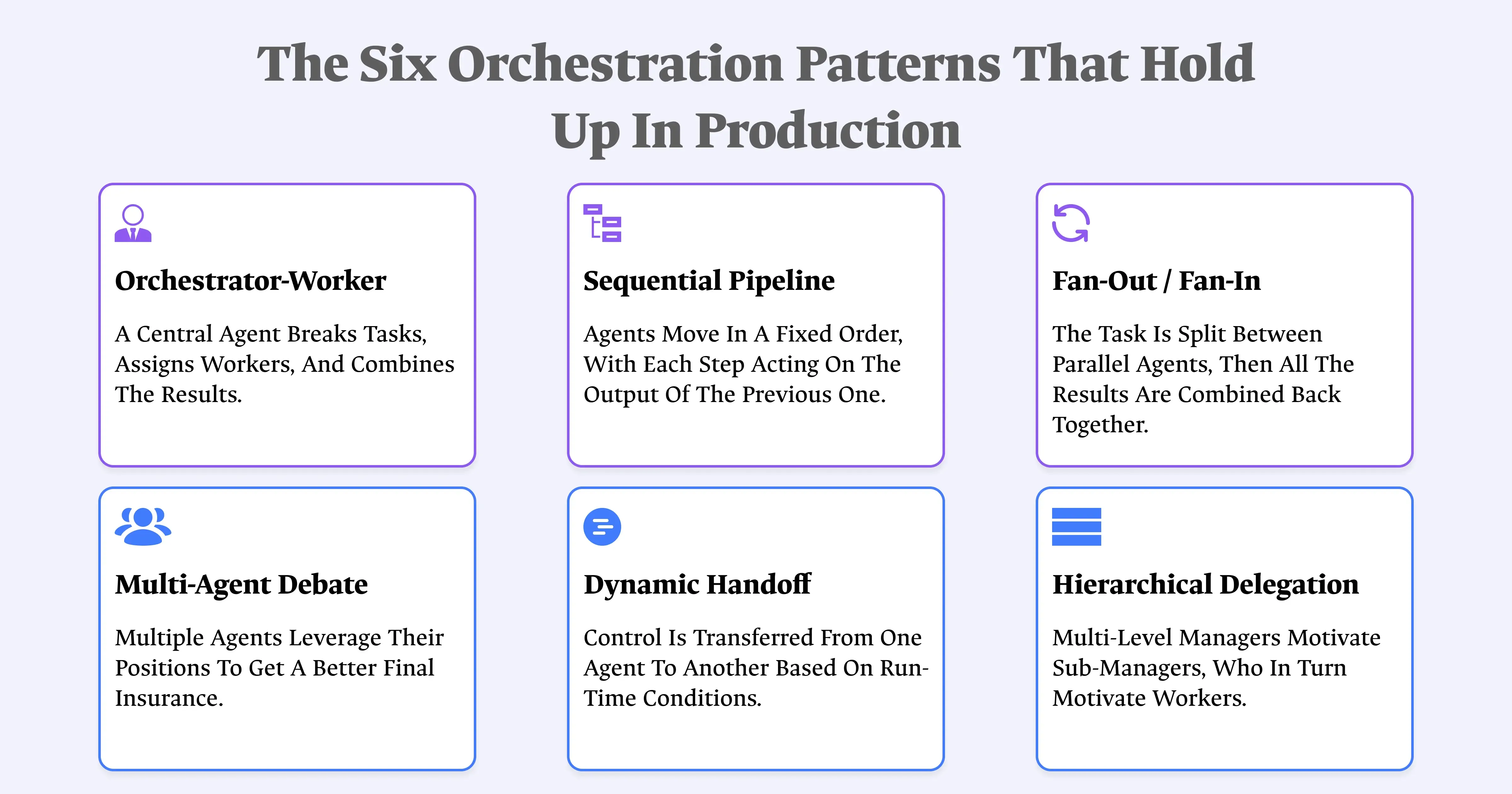
1. Orchestrator-worker
A single orchestrator agent receives the task, breaks it into subtasks, delegates each to a specialized worker, and assembles the results. The orchestrator typically runs a more capable model while workers run cheaper, task-specific ones, which alone can cut costs 40 to 60 percent.
Use this when the subtasks are knowable in advance and you want one clear point of accountability customer service routing between billing, technical, and product specialists is the canonical example. It's also the default pattern shipped by both Anthropic's Claude Agent SDK and OpenAI's Agents SDK, which tells you something about how broadly applicable it is as a starting point.
2. Sequential pipeline
Agents run in a strict, predefined order, each one consuming the previous agent's output. Use this when the order genuinely never changes and each step depends on the last — extract, validate, then match is a pipeline; there's no version of that task where validation usefully happens before extraction.
3. Fan-out/fan-in (parallel dispatch)
The orchestrator dispatches multiple agents to work simultaneously on independent pieces, then synthesizes their results once everything returns. This is the pattern for four or more genuinely independent subtasks comparing a claim against multiple vendor APIs at once, for instance, rather than checking them one at a time.
4. Multi-agent debate (maker-checker)
One agent produces work, a second agent with different instructions sometimes a different model reviews it before it ships. This is the same maker-checker split that matters in loop engineering, applied here across agents instead of across loop iterations. Use it specifically where accuracy matters more than speed: a "reviewer" agent checking code for security flaws, or a fact-checker verifying research claims before they're treated as ground truth.
5. Dynamic handoff
Routing between specialist agents isn't decided in advance it's determined as the conversation unfolds, because you genuinely can't know which specialist is needed until you're partway through the task. This trades the predictability of orchestrator-worker for flexibility on tasks where the right next step only becomes clear once you see how the current step resolved.
6. Hierarchical delegation
This extends orchestrator-worker across multiple levels: a top-level supervisor delegates to mid-level supervisors, each managing its own pool of specialist workers. Authority and context flow downward, results flow back up. Reserve this for genuinely distinct domains of expertise that each need their own sub-supervisor a top-level orchestrator splitting work between a code team lead and a research team lead, each running their own workers underneath. Every additional layer adds coordination overhead, so only add one when the complexity actually demands it, not by default.
Centralized vs. Decentralized Coordination
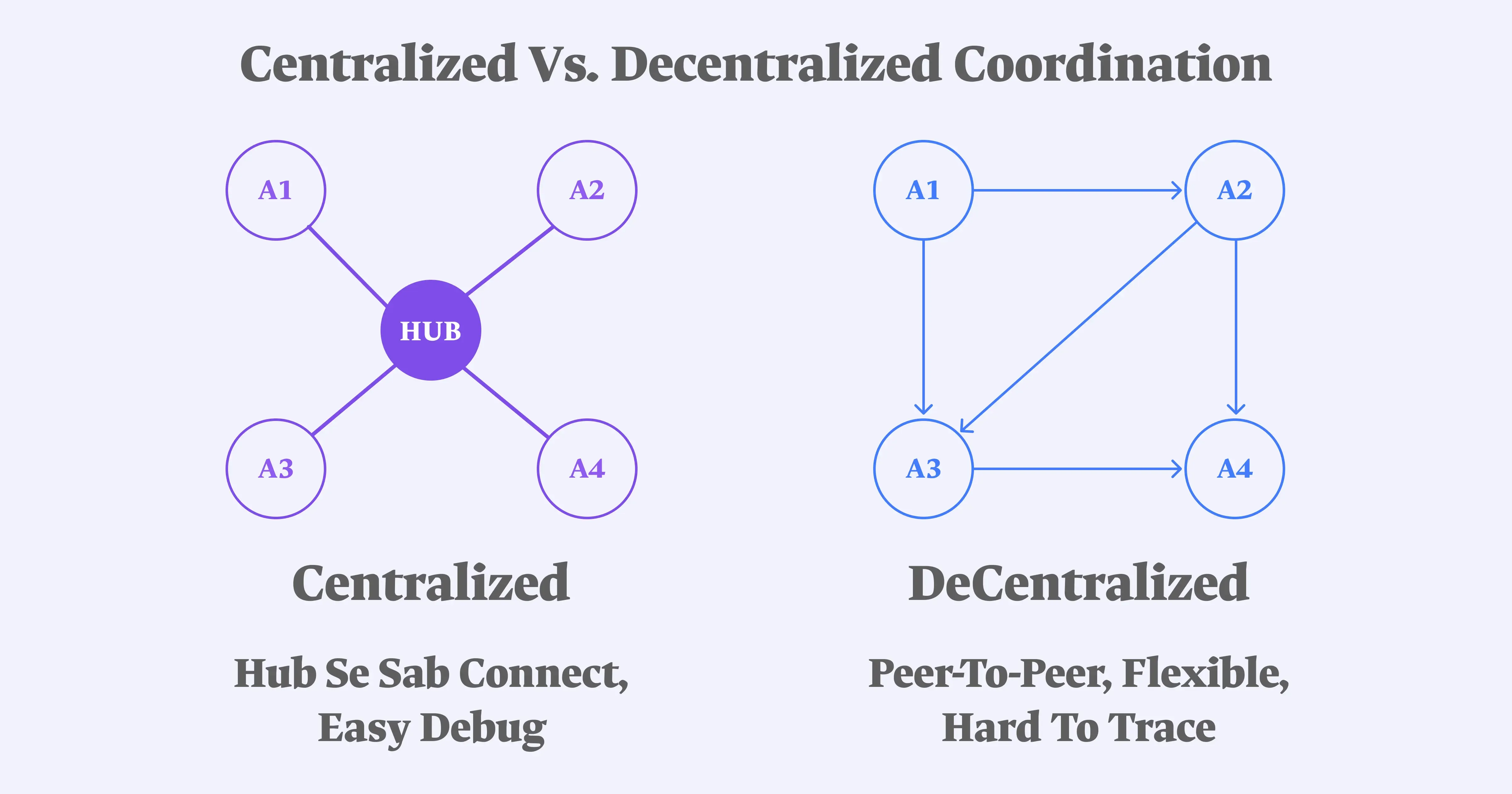
Orchestrator-worker, sequential pipeline, and hierarchical delegation are all centralized: every interaction passes through a hub, which makes debugging tractable because you can trace the full reasoning chain through one place. Dynamic handoff and peer-to-peer patterns are decentralized: agents communicate more directly, which buys flexibility at the cost of traceability reconstructing what actually happened after the fact is significantly harder when interactions are scattered across agent pairs instead of logged through a single node. If you're choosing between a centralized and decentralized pattern and you don't have a strong reason to need the flexibility, the easier-to-debug option is the right default.
How Multi-Agent Systems Actually Fail
Hallucination cascading
This is the failure mode specific to multi-agent systems and arguably the most dangerous one. One agent produces a hallucinated output, and a downstream agent treats it as ground truth not just passing the error along, but elaborating on it and building further conclusions on top of a false premise. A single agent's mistake stays contained to one output. A cascaded hallucination compounds across every agent that trusted it.
The mitigation is structural, not a matter of better prompting: require agents to cite sources explicitly, run independent verification steps rather than trusting upstream output by default, use cross-checking consensus patterns where it matters, and ground critical facts against authoritative external sources at agent boundaries — the seams between agents are exactly where unverified claims need to be caught before they propagate.
Picking the wrong pattern for the task
The research on multi-agent failure is fairly direct on this: it's rarely that multi-agent systems don't work, it's that teams pick the wrong orchestration pattern for their problem, or pick the right one without understanding how it specifically breaks. An orchestrator-worker setup applied to a task that actually needs dynamic routing will misroute work. A fan-out pattern applied to subtasks that secretly have dependencies will produce results that don't reconcile.
Skipping observability
If you can't see what your agents are doing in real time, you can't debug a multi-agent system when it goes wrong — and multi-agent systems go wrong in more ways than single agents, because there are more seams where things can desynchronize. Observability isn't an optional add-on for production multi-agent work; it's the only reason a failure is debuggable instead of just mysterious.
Building the orchestrator before the workers
The more reliable build order is the reverse of how it's tempting to start: build and test worker agents in isolation first, then build the orchestrator to connect them. An orchestrator built around workers that haven't been independently validated inherits every one of their untested assumptions.
Frequently Asked Questions
What is multi-agent orchestration? Multi-agent orchestration is the practice of coordinating multiple specialized AI agents so they divide a task, share context, handle errors at the boundaries between them, and produce one coherent result, rather than relying on a single agent to hold an entire task in one context window.
Is multi-agent orchestration always better than a single agent? No. Research from Princeton NLP found a single agent matched or outperformed multi-agent systems on 64% of benchmarked tasks when given equivalent tools and context. Orchestration is worth its overhead specifically when a task doesn't fit one context window, needs genuinely specialized expertise, or has independent parts that benefit from running in parallel.
What causes most multi-agent systems to fail in production? The most common causes are picking an orchestration pattern that doesn't match the task's actual structure, missing observability into what agents are doing in real time, and hallucination cascading — where one agent's incorrect output gets treated as fact by the agents downstream of it.
What's the difference between orchestrator-worker and hierarchical delegation? Orchestrator-worker is a single supervisor delegating directly to specialist workers. Hierarchical delegation extends that same pattern across multiple levels, with a top-level supervisor delegating to mid-level supervisors who each manage their own workers — useful only when there are genuinely distinct domains of expertise that each need their own coordination layer.
Should I start with a centralized or decentralized orchestration pattern? Start centralized unless you have a specific reason not to. Centralized patterns route every interaction through a single hub, which makes the full reasoning chain traceable and debugging tractable. Decentralized patterns trade that traceability for flexibility, which is only worth it when the routing genuinely can't be predicted in advance.
The Takeaway
The pattern across this whole series has been the same: the leverage point keeps moving up a layer, from typing prompts, to designing the loop that prompts, to managing what an agent sees, to now deciding how several agents divide a task between them. Each layer is real, and each one is also easy to reach for before you actually need it.
Before adopting multi-agent orchestration, check the task against the three conditions that actually justify it. If it passes, start with the simplest pattern that fits — orchestrator-worker for known task decomposition, sequential pipeline for fixed linear steps, fan-out for independent parallel work — and build the workers before the orchestrator that connects them. Most of what sinks multi-agent pilots isn't the idea of coordinating agents. It's coordinating them with the wrong pattern, or coordinating them before a single agent had actually been ruled ou
Written by Numan, a full-stack developer working with Agentic AI, loop engineering, and context engineering for production mobile and web products. Get in touch if you're building something that needs this kind of engineering