Context Engineering: Why It Replaced Prompt Engineering as the Real Skill in 2026
Your AI agent was sharp at step 5. By step 15, it's calling wrong tools, forgetting your instructions, and producing low-quality outputs.
You blame the model. Everyone does.
But after building and breaking hundreds of agents, I can tell you it's almost never the model.
what the model is seeing. Feed it garbage context, it gives you garbage decisions.
There's a name for fixing this: context engineering.
Prompt Engineering Is Dead. Context Engineering Is What Keeps AI Agents Alive.
For a couple of years, the skill everyone wanted was prompt engineering finding the right words to make a model behave. That skill hasn't disappeared, but it's stopped being the thing that decides whether an AI agent actually works in production.
Building with Agentic AI day to day, on real codebases instead of one-off demos, the failure mode I run into is almost never "the model didn't understand the instruction." It's that the agent lost track of something forty turns ago, or got handed too much irrelevant information and started ignoring the part that mattered. That's not a prompting problem. That's a context problem and context engineering is the discipline built around fixing it.
This guide covers what context engineering actually means, why it overtook prompt engineering as the higher-leverage skill, and the concrete techniques from system prompt design to compaction to sub-agent architectures that keep an agent reliable across a long session instead of just a single good reply.
What Is Context Engineering?
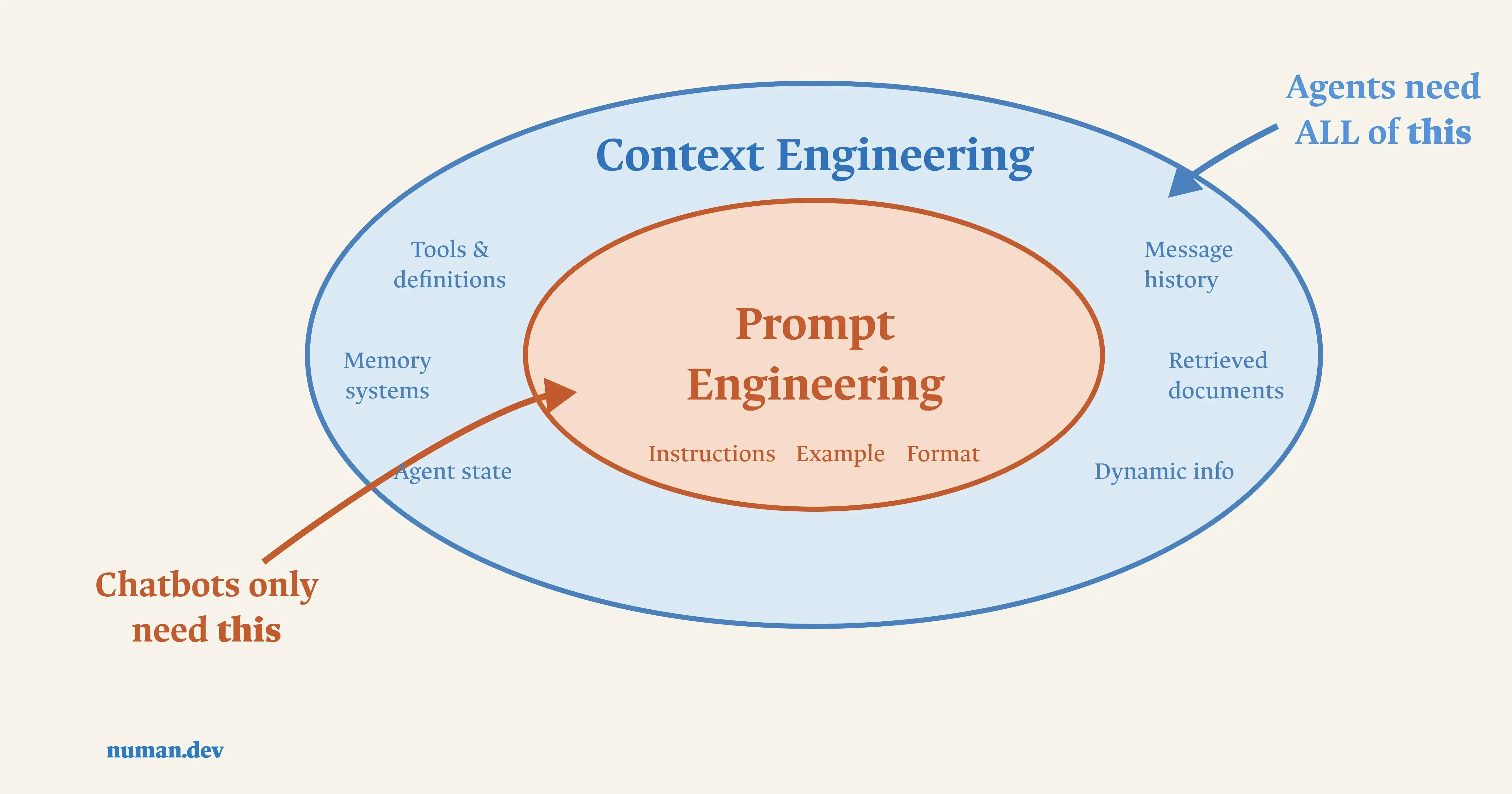
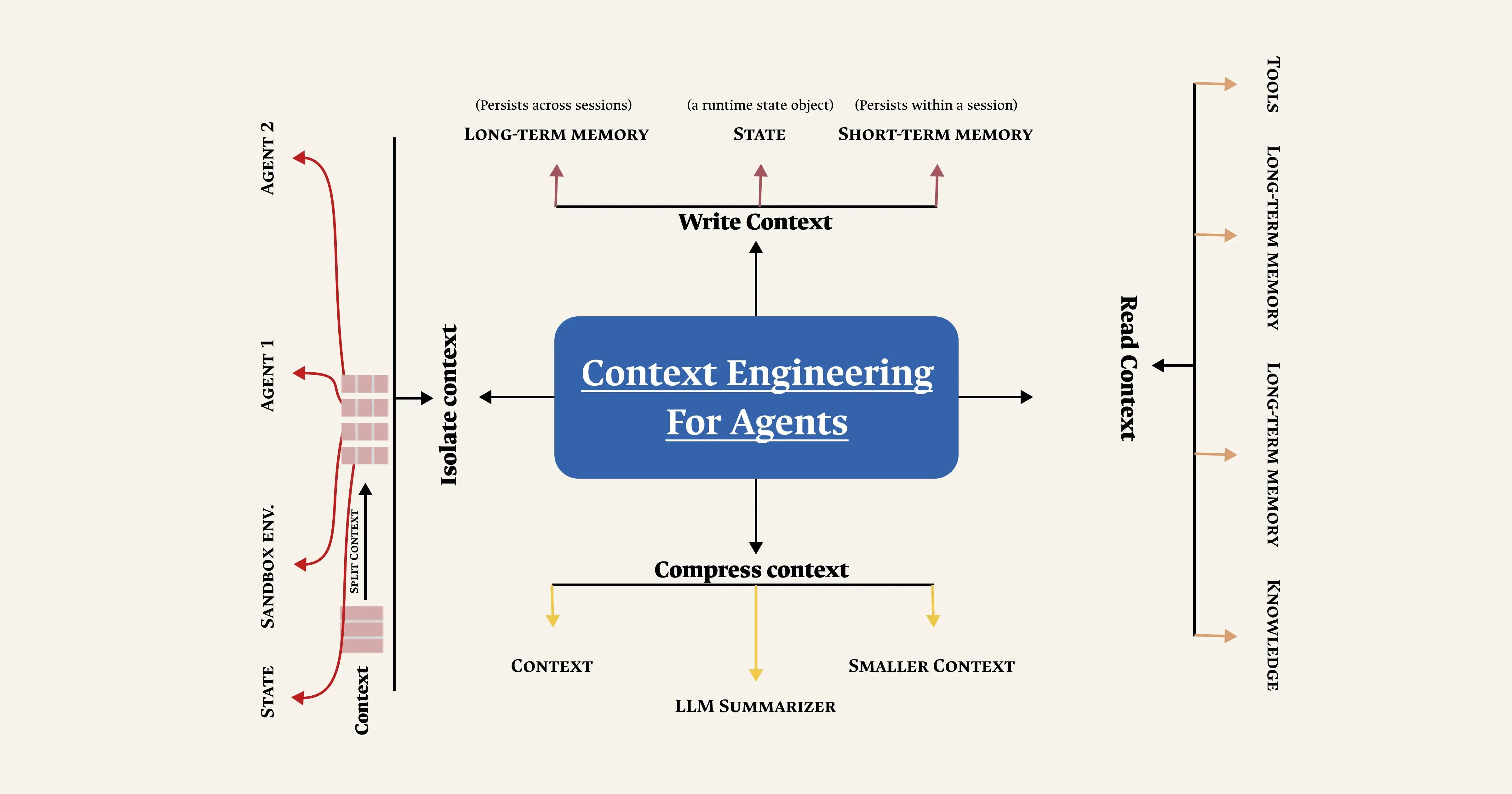
Context engineering is the practice of curating and managing every token a language model sees at inference time system instructions, tool definitions, retrieved documents, message history, and prior outputs so the model has exactly the information it needs to act reliably, and nothing that distracts it.
The shift in framing matters. Prompt engineering asks: what words get the best single response? Context engineering asks a broader question: what configuration of context, across an entire task or session, is most likely to produce the behavior I actually want? One is about phrasing. The other is about architecture.
Why This Became the Core Skill of 2026
Agents today are best understood with a simple definition: a model autonomously using tools in a loop. As models got better at recovering from errors and reasoning over ambiguity, the ceiling on what they could attempt rose but so did the amount of context they accumulate over a session.
Context is a finite resource. Every tool call, every file read, every retrieved document adds tokens to a window that doesn't grow indefinitely, and that the model has to weigh all at once. A model given the right three pieces of context outperforms a model given the right three pieces buried inside thirty irrelevant ones. The engineering problem is no longer "say it well." It's "show it the right things, in the right order, and clear out what it doesn't need anymore."
This is also why context engineering shows up specifically in the harder cases prompt engineering doesn't touch: long-running agents, multi-step coding tasks, and any workflow that spans more than a single exchange.
The Core Components of Context
Effective context engineering treats every part of what a model sees as a deliberate design choice, not a default.
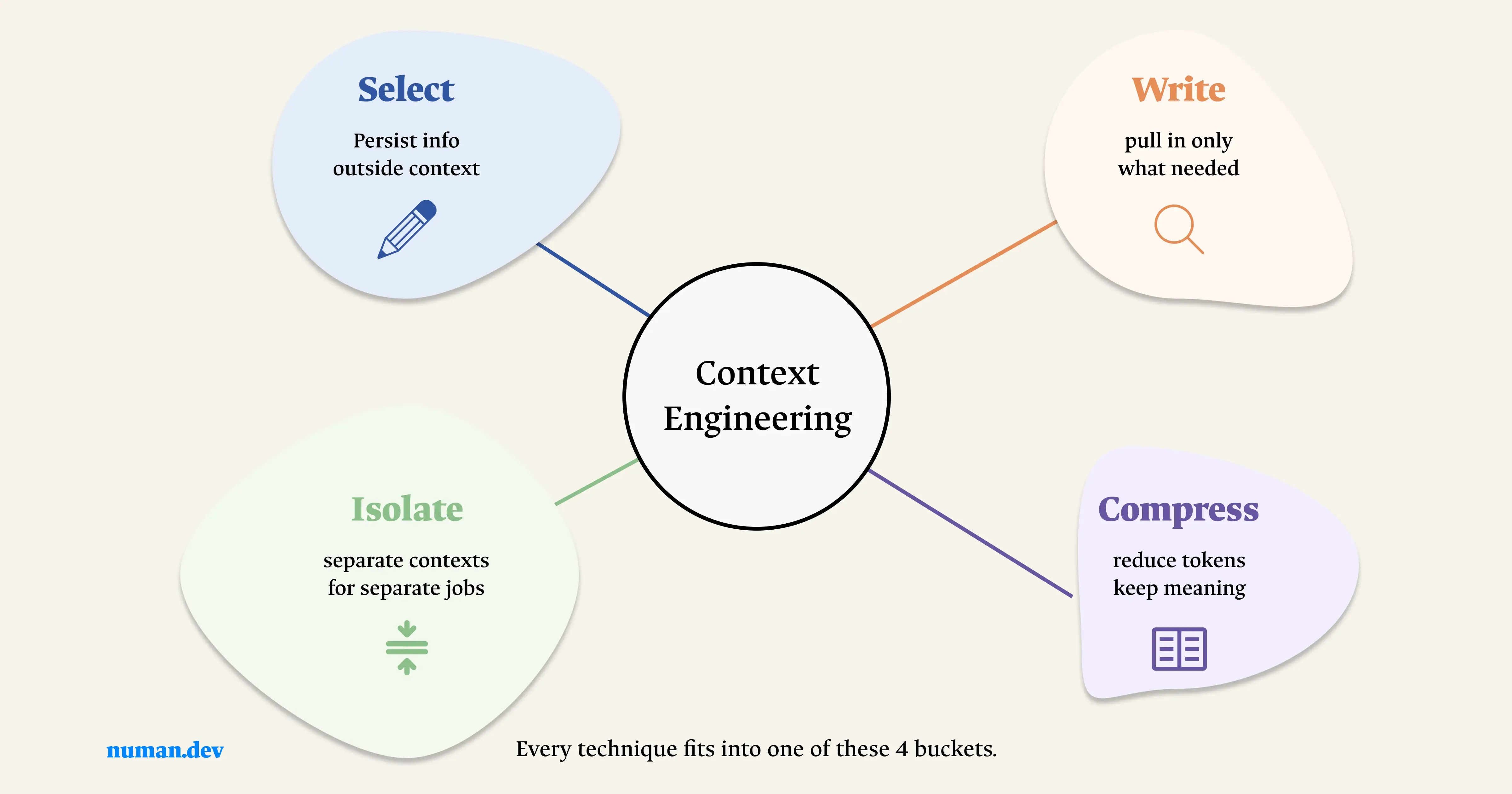
Select
Most agent failures trace back to one decision made too early putting everything into context and hoping the model sorts it out. It doesn't. I've built enough agents to know that what you leave out matters just as much as what you put in. Your system prompt should guide behavior without turning the model into a rule-follower. Your toolset should be small enough that every function has one obvious job. Selection is the first place context engineering either works or falls apart.
Write
The way you write your context determines how your agent behaves when things get complicated. Loose instructions produce loose decisions and by turn 20 that looseness compounds into something you can't trust. A few real, specific examples of what good output looks like will do more than ten paragraphs of rules. Write like you're briefing someone sharp who's never seen this task before. Clear, direct, no filler.
Isolate
Here's what nobody tells you about long agent sessions the context keeps everything. Resolved errors, outdated decisions, tool outputs from six turns ago that no longer apply. The model reads all of it. Weighs all of it. And sometimes trusts the old stuff over what you just told it. Isolating what's still true and actively removing what isn't is one of the highest-leverage things you can do for agent reliability.
Compress
Every session starts clean and gets heavy fast. By the time you're deep into a long run, your context is carrying transcripts, resolved threads, and decisions that got reversed three turns ago. Compression isn't about losing information it's about keeping what the model actually needs and dropping everything it doesn't. Summarize what's done. Clear what's stale. A lean context at turn 40 performs closer to turn 5 than most people expect.
Why Long Sessions Quietly Fall Apart
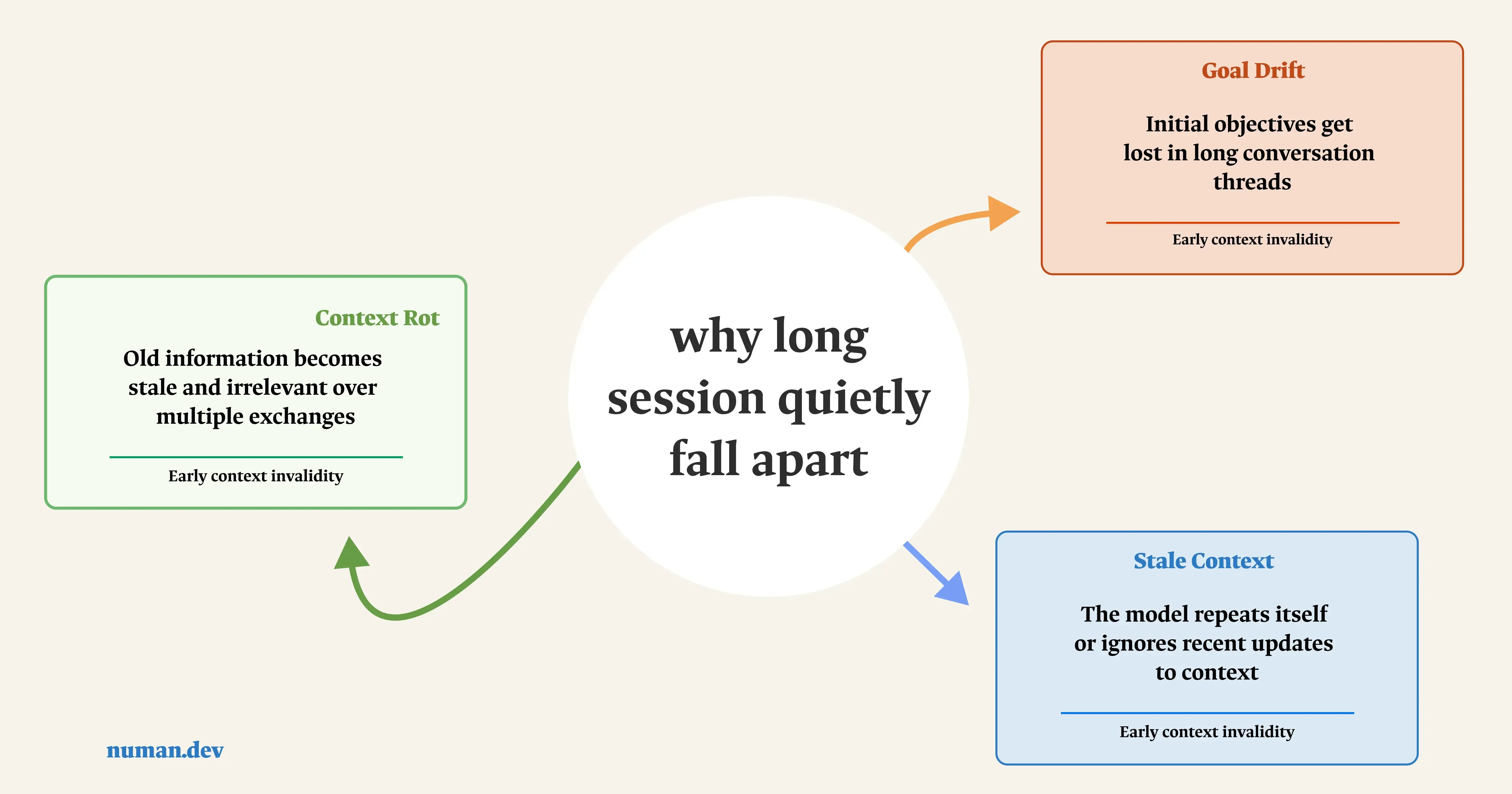
The core challenge with long-running agents is structural: they work in discrete sessions, and each new session starts with no memory of the last one. It's the same problem as a project staffed by engineers working in shifts, where every new engineer arrives knowing nothing about what the previous shift just did.
Three specific failure patterns show up repeatedly in practice:
Context rot
As the window fills with turns, tool outputs, and intermediate reasoning, the signal-to-noise ratio drops. The model technically still has access to the early instruction that mattered, but it's now buried under thousands of tokens of less relevant material.
Goal drift
Constraints stated early in a session don't touch the payments code always run the linter before committing get summarized away during context compression, or simply outweighed by more recent turns. The model isn't ignoring the rule; it no longer has a strong enough signal that the rule exists.
Stale context
Information that was true at turn five is presented with the same weight as information from turn fifty, even after it's been superseded. A file path that changed, a decision that got reversed, an error that's already fixed without active pruning, all of it stays in the window competing for attention.
Show Image
Techniques That Actually Manage Context

Compaction
Compaction summarizes a conversation as it approaches its context limit and reinitializes a new window with that summary, preserving architectural decisions and unresolved issues while discarding redundant tool outputs and superseded content. Done well, this is the difference between a session that degrades gracefully past turn fifty and one that simply falls over.
Structured note-taking
An agent that writes persistent notes outside the context window a NOTES.md, a task list, a running log of decisions — can pull that information back in later without needing it to survive inside the active window the whole time. This is the same principle behind a state file in a loop: the agent forgets, the file doesn't.
Sub-agent architectures
Complex tasks can be split across multiple agents, each operating in its own context window, with a single orchestrator passing distilled summaries between them rather than sharing one giant accumulating window. A research sub-agent can explore dozens of sources in its own context and report back a condensed result, instead of polluting the main agent's window with every page it read along the way.
Just-in-time retrieval
Rather than pre-loading everything an agent might need, maintaining lightweight identifiers file paths, stored queries, links — and retrieving the actual content only at the moment it's needed keeps the window leaner and the retrieved information fresher.
Tool curation
Fewer, more deliberately scoped tools consistently outperform a sprawling toolkit. If two tools could plausibly apply to the same situation, that ambiguity is a tax the model pays on every decision, not a one-time cost.
Context Engineering vs. Prompt Engineering
What's the difference between context engineering and prompt engineering? Prompt engineering optimizes the wording of a single instruction to get a better response. Context engineering optimizes the entire set of information — instructions, tools, history, retrieved data — available to the model across a task, including how that information is curated and refreshed over time.
Did context engineering replace prompt engineering?
Not exactly prompt engineering is now a subset of context engineering rather than a separate discipline. Writing a clear instruction still matters; it's just no longer sufficient on its own once a task spans multiple turns, tool calls, or sessions.
Why do AI coding agents lose track of instructions in long sessions?
Usually one of three reasons: the relevant instruction gets diluted by accumulated context (context rot), it gets summarized away during compaction (goal drift), or it's been superseded by newer information that the model weighs equally with the original (stale context).
Practical Habits for Working With Agents Day to Day
For anyone building with coding agents rather than just researching the theory, a few habits make the biggest practical difference:
Keep system prompts and tool descriptions specific but not brittle exact enough that the agent doesn't guess wrong, loose enough that it can still apply judgment to cases you didn't anticipate. Write persistent notes for anything that needs to survive past the current context window, the same way a state file survives past a single loop run. Periodically review what's actually sitting in an agent's context during a long task stale file contents and resolved errors that never got cleared out are a common, invisible source of bad output. And treat your toolset the way you'd treat an API surface: every tool you add is a tool the model has to correctly choose not to use in every other situation.
The Takeaway
The leverage moved once already from typing every step manually to designing loops that run agents on a schedule. It's moving again, one level deeper: into the discipline of deciding exactly what an agent sees, when it sees it, and what gets cleared out before it starts working against you.
Prompt engineering didn't go away. It just stopped being the whole job. The teams getting reliable results from agents in 2026 are the ones treating context not just instructions as something they actively design.
Written by Numan, a full-stack developer working with Agentic AI and loop engineering, React Native, and Node.js for production mobile and web products. Get in touch if you're building something that needs this kind of engineering.